
W świecie idealnych rozwiązań informatycznych firmy skupiają się na rozwijaniu biznesu, a pracownicy działów IT kontrolują procesy informatyczne oraz biorą udział w coraz ciekawszych projektach optymalizacyjnych. Taka sytuacja wymaga jednak, abyśmy dysponowali środowiskiem informatycznym przygotowanym do pracy w trybie ciągłym, dostosowanym do różnych poziomów niedostępności, utrudnień w działaniu i odpornym na awarie.
Ciągłość działania to pojęcie względne. Dla niektórych branż niedostępność systemu liczona w kilku godzinach w skali roku jest akceptowalna. Dla innych, np. usług finansowych czy logistyki magazynowej, gdzie liczba transakcji liczona jest w dziesiątkach tysięcy komunikatów dziennie, wymagane są znacznie wyższe poziomy dostępności.
Czy jest możliwe zapewnienie wysokiej dostępności, jeżeli posiadamy własne centrum danych w jednej lokalizacji, a wymogiem pochodzącym z wnętrza organizacji jest, aby główne systemy informatyczne pracowały nieprzerwanie w trybie 24/7? Czy dobrym pomysłem będzie umieszczenie systemów centralnych, w których istotna jest dostępność i spójność danych, w rozwiązaniach chmurowych, nawet największych dostawców? Czy w przypadku awarii sprzętowej będziemy mogli szybko odtworzyć system do stanu sprzed awarii? To pytania, na które firma musi znaleźć odpowiedzi, planując strategię utrzymania systemów IT.
Ciągłość działania
Zapewnienie ciągłości działania wymaga przemyślenia architektury oraz warunków brzegowych koniecznych do zapewnienia dostępności naszych systemów. Najważniejsze aspekty, jakie należy wziąć pod uwagę, to:
- plan działania na wypadek awarii (zwany Planem Ciągłości Działania – Disaster Recovery Plan, DRP) – czyli spisana krok po kroku procedura odzyskiwania ciągłości działania;
- Zapasowe Centrum Danych (Disaster Recovery Center, DRC) – czyli miejsce, w którym odzyskamy ciągłość działania;
- testowanie planów ciągłości działania – ma na celu przetestowanie procedur zapisanych na papierze w celu lepszego ich zapamiętania, poprawy i szybszego uruchomienia w realnym scenariuszu;
- posiadanie odpowiedniego rozwiązania, które w połączeniu z wymaganiami RTO (Recovery Time Objective) i RPO (Recovery Point Objective) pozwoli na sprostanie wymaganiom organizacji.
Uwzględniając powyższe kwestie bezpieczeństwa, a także dostępny budżet, możemy zaplanować architekturę systemów zakładającą umieszczenie danych w różnych ośrodkach danych.
Najwięksi dostawcy usług chmurowych chwalą się dostępnością na poziomie 99,999%. Niektórzy podają nawet SLA na poziomie siedmiu dziewiątek, co – w teorii przynajmniej – pozwala liczyć niedostępność systemu w pojedynczych sekundach w skali roku. Imponujące. Jednak gdy wczytać się w warunki kontraktu, okazuje się, że taki parametr jest gwarantowany tylko dla pojedynczych elementów usługi, w zależności od parametrów infrastruktury. To trochę jak z producentem samochodu, który w reklamach oferuje kilka lat gwarancji i dopiero czytając umowę kupna auta, przekonujemy się, że owszem, ale tylko dla wybranych elementów zawieszenia i niektórych systemów bezpieczeństwa. Gwarancja nie obejmuje np. karoserii, hamulców czy np. sprzętu audio.
Nawet centrum danych z najwyższym poziomem dostępności nie zapewni nam szybkiego powrotu do działania kluczowych systemów w przypadku uszkodzenia całej macierzy dyskowej, jeśli kupiliśmy usługi bez replikacji danych. Obecnie rozwiązania macierzowe to często dziesiątki, setki a czasem tysiące terabajtów danych. Utrata całej macierzy może wiązać się z wielogodzinnym lub nawet wielodniowym odtwarzaniem danych z kopii bezpieczeństwa w inne miejsce, o ile takie jest dostępne.
Usługi zarządzane w SNP (aktualnie All for One Poland)
Dobrze zaplanowana i skonstruowana platforma sprzętowo-programowa, w połączeniu z rozwiązaniem wysokiej dostępności przestrzeni dyskowych, pozwala na zachowanie ciągłości działania systemów informatycznych wykorzystywanych w przedsiębiorstwie.
Z takiego wydajnego i bezpiecznego środowiska mogą korzystać nasi klienci. W ramach All for One Managed Cloud jesteśmy w stanie dostarczyć zindywidualizowany pakiet usług chmurowych, hostingowych i administracyjnych. Dwa bliźniacze centra przetwarzania danych w różnych lokalizacjach pozwalają na realizację Centrum Przetwarzania Danych, z pełną replikacją systemów i danych bez żadnych opóźnień.

Tomasz Wawrzonek, Zastępca Dyrektora IT, All for One Poland
Dla wymagających systemów
Rozwiązania VMware Metro Storage Cluster to kolejny etap rozwoju naszej oferty biznesowej usług Managed Cloud dla coraz bardziej wymagających klientów. Dzięki infrastrukturze All for One Data Centers i VMware Metro Storage Cluster możemy adresować oczekiwania dla najbardziej wymagajcych i krytycznych systemów IT, a takimi niewątpliwie są systemy SAP. Również nasze rozwiązania SaaS, takie jak BeeOffice, Edistrada czy Rockawork, korzystają z powyższej architektury wysokiej dostępności.
Tomasz Wawrzonek, Zastępca Dyrektora IT, All for One Poland
Środowisko systemów w All for One Data Centers jest w pełni zwirtualizowane. Wykorzystując zalety chmury prywatnej, nasi klienci nie są uzależnieni od konkretnego komponentu sprzętowego, na którym uruchomiony jest ich kluczowy system biznesowy. Macierze dyskowe z możliwością replikacji (synchronicznej lub asynchronicznej) umożliwiają stworzenie aktualnej kopii danych w drugim centrum bez żadnych opóźnień. Dla wielu naszych klientów takie rozwiązanie realizuje w pełni ich potrzeby biznesowe. Co jednak, jeżeli firma posiada rozbudowane środowiska bazodanowe oraz systemy wymiany danych transakcyjnych? Przerwa w pracy kilkunastu środowisk jednocześnie może spowodować również wielkogodzinne przełączenia i rekonfiguracje maszyn pomiędzy macierzami.
Aby zapewnić klientom wysoką dostępność ich systemów i danych pracujących w All for One Managed Cloud, zdecydowaliśmy się na uruchomienie rozwiązania VMware Metro Storage Cluster, wraz z odpowiednim certyfikowanym rozwiązaniem systemów macierzowych. Konfiguracja VMware Metro Storage Cluster to certyfikowane rozwiązanie VMware, które łączy replikację danych z zapewnieniem wysokiej dostępności na poziomie maszyn wirtualnych, czyli systemów IT.
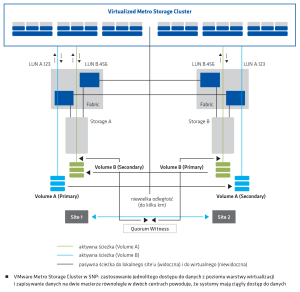
Dzięki zastosowaniu jednolitego dostępu do danych z poziomu warstwy wirtualizacji i zapisywaniu danych na dwie macierze równolegle w dwóch centrach systemy mają ciągły dostęp do danych. Nawet w przypadku awarii jednego z dwóch centrów przetwarzania danych SNP (aktualnie All for One Poland) i jednej macierzy całość danych jest dostępna do dalszej pracy na drugiej macierzy praktycznie bezprzerwowo (w czasie 5-20 sekund).
Konfiguracja VMware Metro Storage Cluster w All for One Managed Cloud to wyróżnik naszej oferty chmury prywatnej dla systemów biznesowych. Deklarowana przez SNP wysoka dostępność dotyczy obecnie całej infrastruktury data center, a nie wybranych parametrów. Rozwiązanie to pozwala nam spełniać oczekiwania wysokiej dostępności systemów i danych dla najbardziej wymagających branż i klientów. Ograniczamy do minimum czasy niedostępności systemów w sytuacji masowej awarii, a nawet całkowitego wyłączenia jednego z dwóch site’ów. Nie ma potrzeby odtwarzania wirtualnych maszyn z kopii zapasowych.