
Duża część przedsiębiorstw w dalszym ciągu ogranicza się wyłącznie do analizy danych historycznych, ich wizualizacji i obliczania, w oparciu o nie wskaźników efektywności w bieżącym i poprzednich okresach. Tymczasem gromadzone dane pozwalają na predykcję, czyli przewidywanie przyszłości. To właśnie wiedza o tym, z jakim prawdopodobieństwem wystąpią określone zjawiska, może realnie wspomóc proces podejmowania decyzji dotyczących dalszego rozwoju firmy, zarówno na szczeblu operacyjnym, jak i strategicznym. Jak wykazały badania przedsiębiorstwa, które wykorzystują analizę predykcyjną w swoich kampaniach sprzedażowych, są prawie dwukrotnie bardziej efektywne od firm, które posługują się jedynie tradycyjnymi metodami marketingowymi.
Gdzie wykorzystać?
Nie tylko w dziale marketingu analiza predykcyjna znajduje zastosowanie. Algorytmy predykcyjne sprawdzą się w monitorowaniu procesu produkcji, planowaniu dostaw, w ocenie ryzyka finansowego czy przewidywaniu przychodów ze sprzedaży. Wykorzystane mogą być zarówno w podmiotach zajmujących się sprzedażą detaliczną, w ośrodkach zdrowia (np. do prognozowania rozprzestrzenia się chorób), w sektorze publicznym (np. do analizy przestępczości), w bankowości (do zarządzania ryzykiem i segmentacji klientów), w ubezpieczeniach (np. do analizy roszczeń) czy wreszcie w przedsiębiorstwach produkcyjnych (np. do optymalizacji procesu produkcji).
SAP Predictive Analytics w celu przeprowadzenia wymienionych analiz, dostarcza szereg wbudowanych funkcji ułatwiających budowę modelu i automatyzację całego procesu predykcji. Wbudowane funkcje pozwalające na przygotowanie danych, ich wizualizację oraz dostępne algorytmy sprawiają, że budowa modeli regresji, drzew decyzyjnych, analiza szeregów czasowych, segmentacja klientów, analiza koszykowa czy posługiwanie się sieciami neuronowymi nie jest czasochłonne. Nie wymaga od użytkownika znajomości zaawansowanych metod statystycznych oraz ekonometrycznych. Jednocześnie SAP Predictive Analytics pozwala również na pisanie własnych programów w przypadku konieczności budowania skomplikowanych modeli. Umożliwia posługiwanie się skryptami R oraz SAP HANA APL (Automated Predictive Library). Jako jedyne narzędzie tej klasy zapewnia natywną integrację z oprogramowaniem SAP, a w szczególności z SAP HANA, SAP S/4HANA, SAP BusinessObjects i SAP BW.
Grupy użytkowników
W dużych podmiotach gospodarczych istnieją zazwyczaj trzy grupy użytkowników analizy predykcyjnej. Zdecydowaną większość (ponad 95%) stanowią użytkownicy biznesowi, których wiedza z zakresu stosowania zaawansowanych metod statystycznych, ekonometrycznych czy data mining jest stosunkowo niewielka. Jedynie nieliczna grupa pracowników umie się nimi posługiwać lub wręcz są ekspertami od metod ilościowych. By spełnić oczekiwania wszystkich grup użytkowników SAP Predictive Analytics umożliwia pracę w dwóch modułach: automatycznym i eksperckim. W pierwszym przypadku proces przygotowywania danych, budowy modelu czy jego wykorzystania jest przeprowadzany metodą „krok po kroku” i wymaga od użytkownika jedynie minimalnej konfiguracji i parametryzacji. W module eksperckim proste modelowanie jest również możliwe, ale jednocześnie zaawansowane metody przygotowania danych czy wykorzystanie własnych lub pozyskanych z sieci skryptów R może być wykorzystane. Szczegóły pracy z oboma modułami zaprezentowane zostały w części praktycznej artykułu.
W aplikacji można wykorzystywać dane pochodzące z:
- źródeł plikowych (*.xls, *.xlsx, *.csv, *.txt, *.log, *.prn, *.tsv),
- schowka,
- świata obiektów BO,
- hurtowni danych SAP BW,
- relacyjnych baz danych (poprzez zapytania SQL),
- SAP HANA.
Warto zaznaczyć, że w przypadku korzystania z danych znajdujących się w SAP HANA możliwe są dwie opcje, tj. pobranie danych lub połączenie bezpośrednio z bazą.
Na podstawie otrzymanych wyników można utworzyć wizualizacje i raporty, które mogą być publikowane i udostępniane innym użytkownikom poprzez:
- Pliki: CSV, EXCEL, PDF,
- Platformę BI,
- SAP HANA,
- SAP Analytics Cloud,
- SAP Lumira Server.
Zautomatyzowany proces modelowania nie oznacza braku możliwości oceny właściwości predykcyjnych modelu. Wręcz przeciwnie – w module automatycznym SAP Predicitve Analytics dla każdego modelu obliczane są dwie miary: siła predykcji (Ki) i ufność predykcji (Kr). Pierwsza z nich (Ki) jest miarą specyficzną oprogramowania i mierzy zdolność wyjaśniania wartości zmiennych docelowych przez zmienne objaśniające. Przyjmuje wartości od 0 do 1, a im wyższa jej wartość, tym model jest lepiej dopasowany do danych. Z kolei ufność predykcji Kr mierzy zdolność modelu do bycia tak samo efektywnym dla nowego zbioru danych, jak dla danych testowych. Uznaje się, że model może być wykorzystywany do prognozowania czy implikacji w innym zbiorze danych, jeśli wartość tego wskaźnika jest większa od 0,95. W przypadku modułu eksperckiego obliczane są standardowe testy statyczne służące do oceny istotności poszczególnych parametrów (np. test t studenta) jak i całego modelu (np. współczynnik R2).
Ponadto SAP Predictive Analytics pozwala na automatyzację procesu zarządzania modelami. W tym celu w wersji desktopowej udostępniony jest data manager, który umożliwia tworzenie dynamicznych zbiorów danych i tym samym zwiększa efektywność wykorzystania modeli dla innych przedziałów czasu czy innych obiektów. W wersji klient-serwer oprogramowania załączony jest z kolei Predictive Factory, który umożliwia import modeli, segmentację szeregów czasowych, automatyczne testowanie odchyleń, prognozowanie oraz monitorowanie wydajności modeli i tworzenie harmonogramów.
Istnieją cztery możliwości instalacji SAP Predictive Analytics:
- Wersja Desktopa
Może być zainstalowana na systemie 64-bitowym. Obejmuje oba moduły, tj. analizę ekspercką i automatyczną.
- Klient/Server (bez bazy HANA)
Istnieje możliwość zainstalowania wersji desktopowej SAP PA na tej samej maszynie co wersja klient/serwer w przypadku chęci korzystania z modułu eksperckiego. W tej wersji możliwe jest również korzystanie z Predictive Factory, który umożliwia harmonogramowanie i automatyzację procesu zarządzania modelami.
- SAP PA dla HANA
Niewątpliwymi zaletami tej instalacji jest przeliczanie modeli automatycznych i skryptów R po stronie SAP HANA. Dodatkowo istnieje możliwość skorzystania z biblioteki APL (Automated Predictive Library), która jest dedykowana zapewnieniu wydajności obliczeniowej dla dużych zbiorów danych.
- SAP PA dla SAP HANA w chmurze
Umożliwia instalację narzędzia w oparciu o SAP HANA HEC (HANA Enterprise Cloud) lub HCP (HANA Cloud Platform).
W celu zaprezentowania łatwości użycia obu modułów w praktyce i ich możliwości poniżej przedstawiono opis dwóch przypadków budowy modeli z wykorzystaniem SAP Predictive Analytics w wersji 3.1.
Przypadek 1 – segmentacja klientów
Fikcyjne przedsiębiorstwo X postanowiło poprawić efektywność swoich działań marketingowych i kierować oferty promocyjne dostosowane do preferencji oraz możliwości poszczególnych grup klientów. Już kilka lat temu wprowadziło ono dla swoich stałych klientów karty lojalnościowe. Klienci podczas wypełniania wniosku o kartę podają informacje m.in. na temat swojego wieku, wykształcenia, zawodu, statusu cywilnego, płci itp. Dodatkowo na samej karcie lojalnościowej widoczne są wydatki poniesione przez nich w przeciągu okresu korzystania. Oba rodzaje danych przedsiębiorstwo może wykorzystać by utworzyć klastry dla poszczególnych grup klientów. W tym celu wykorzysta ono moduł automatyczny SAP Predictive Analytics i pliki tekstowe z odpowiednimi danymi. Poniżej zaprezentowano kroki, które należy wykonać.
- Wybór rodzaju modelu
W tym wypadku z pośród dostępnych algorytmów wybrano model klastrów. Po jego wyborze wizard przeprowadza użytkownika przez konfigurację modelu metodą krok po kroku.
- Wskazanie źródła danych
Przedsiębiorstwo X zdecydowało się wykorzystać dane pochodzące z pliku CSV. W programie istnieje możliwość podglądu danych, uzupełnienia brakujących wartości, przetłumaczenia poszczególnych kategorii czy ustawienia filtra ograniczającego zbiór danych do dalszej analizy.
- Wybór zmiennych
Domyślnie wszystkie zmienne (poza numerem klienta) ze zbioru danych mają w przypadku tego modelu status zmiennych objaśniających. Z tego zestawu część zmiennych można przerzucić metodą drag & drop do sekcji zmiennych docelowych lub wykluczyć z dalszej analizy. Wskazanie zmiennej wynikowej nie jest w przypadku modelu klastrów konieczne, ale bez tego program nie będzie w stanie obliczyć miar efektywności modelu: Kr i Ki. Ponieważ celem przedsiębiorstwa X jest to, by klienci jak najwięcej kupowali, to właśnie poniesione przez nich wydatki ustawione zostały jako zmienna wynikowa. Należy pamiętać, by zmiennych objaśniających nie tylko w tego rodzaju modelu, ale także i w innych nie było zbyt dużo, gdyż to utrudnia interpretację otrzymanych wyników.
- Wskazanie liczby klastrów, które mają być wyodrębnione na podstawie modelu
Nie trzeba podawać pojedynczej wartości, a przedział. Wówczas program oszacuje modele dla każdej wartości z podanego zakresu osobno i wskaże, który z nich będzie najlepszy. Liczba wskazanych klastrów do modelu zależy od przesłanek biznesowych i możliwości skonstruowania określonej liczby dedykowanych ofert marketingowych.
- Wybór właściwego modelu
Po zakończonych obliczeniach system wskazuje dla poszczególnych modeli wartości miary Ki i Kr oraz ile procent klientów nie zostało przypisanych do żadnego z utworzonych klastrów. Na podstawie sumy miar ufności i siły predykcji automatycznie zostaje wybrany model najlepszy – w analizowanym przypadku dla siedmiu klastrów.
Wybór właściwego modelu (dla siedmiu klastrów)
- Analiza wyników modelu
Otrzymane wyniki można w łatwy sposób przeanalizować wyświetlając profile poszczególnych klastrów czy zbiorcze statystki. Dzięki profilom możemy m.in. się dowiedzieć, że w analizowanym przypadku najwięcej klientów zostało zakwalifikowanych do klastra 6 (23,58%), a ich wiek jest pomiędzy 47 a 90 lat.
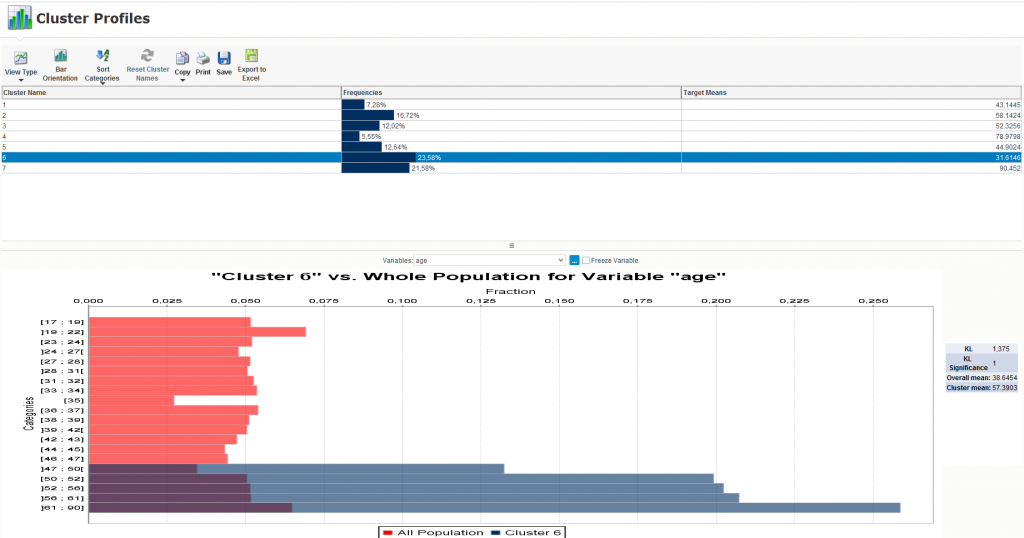
Analiza wyników modelu
Z kolei sekcja raportów statystycznych wskazuje m.in., które zmienne były najbardziej istotne w przypadku wyodrębniania poszczególnych klastrów. W naszym przypadku okazało się, że wiek jest zmienną najbardziej znaczącą w przypadku definiowania klastra 1, 2, 4, 5 czy 6, zaś status cywilny w przypadku klastra 3. Możliwe jest także wyświetlenie wykresu obrazującego wielkość poszczególnych klastrów i ich umiejscowienie na osi układów współrzędnych względem dwóch zmiennych, np. wieku i wydatków.
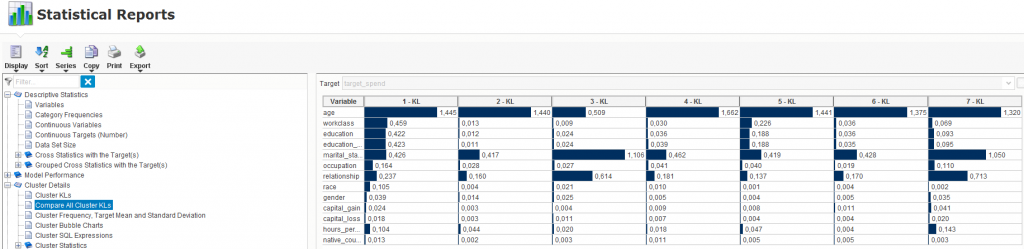
Analiza wyników modelu w przypadku klastra 3
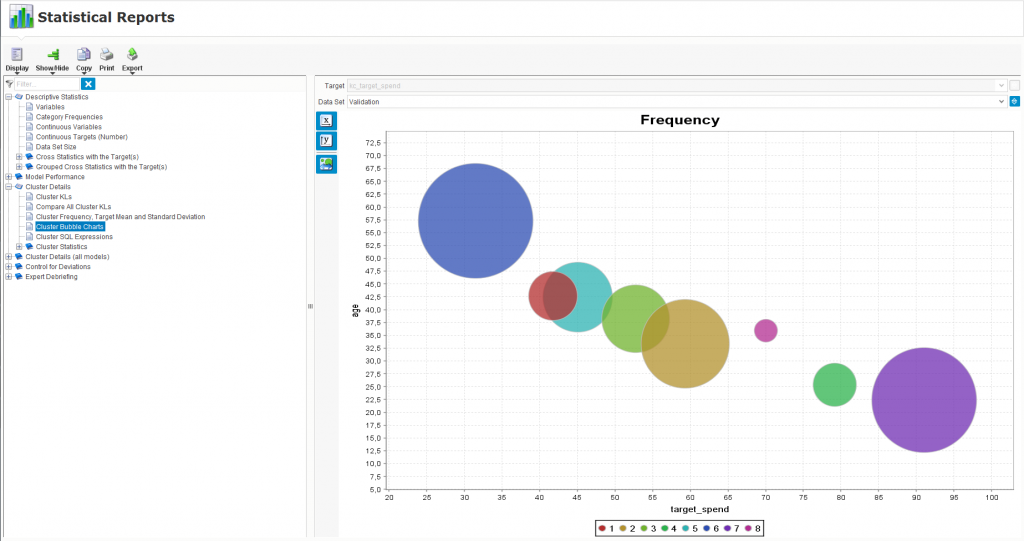
Wykres obrazujący wielkość poszczególnych klastrów i ich umiejscowienie na osi układu współrzędnych
- Zastosowanie modelu do nowego zbioru danych
Po zapisaniu modelu możliwe jest jego wielokrotne wykorzystanie dla nowych klientów, którzy wypełnili wniosek o kartę lojalnościową, ale nie dokonali jeszcze żadnych zakupów z jej użyciem. Po wskazaniu pliku z nowym zestawem danych jako wynik działania modelu otrzymujemy przypisanie klientów do poszczególnych klastrów. Pozostaje tylko wykorzystanie tej informacji w praktyce.
Przypadek 2 – prognoza przychodów ze sprzedaży
Fikcyjne przedsiębiorstwo Y miało za zadanie oszacować swoje przychody ze sprzedaży na kolejne 12 miesięcy. Prognozę tą postanowiło uzyskać na podstawie analizy szeregów czasowych i modelu wygładzenia dla trendu oraz sezonowości. Możliwe byłoby również do tego celu zastosowanie modelu regresji i tym samym uzależnienie przychodu od innych zmiennych. Firma zdecydowała się wykorzystać moduł ekspercki SAP Predictive Analytics, do którego pozyska dane bezpośrednio z hurtowni danych SAP BW. Poniżej zaprezentowano kroki, które należy wykonać w celu otrzymania wyników.
- Wybór źródła danych
Z pośród możliwych źródeł danych przedsiębiorstwo Y zdecydowało się na wybór danych bezpośrednio z hurtowni SAP BW. Po zalogowaniu program SAP Predictive Analytics uzyskuje dostęp do zapytań zdefiniowanych w narzędziu BEX Query Designer na tym systemie.
- Wskazania miar i wymiarów do analizy
Z pośród wszystkich wskaźników i cech zdefiniowanych w wybranym zapytaniu należy wskazać te, które mają być wykorzystane w dalszej analizie. Ponieważ przedsiębiorstwo Y jest zainteresowane analizą sprzedaży w oparciu o dane miesięczne, jako jedyną miarę wskazało Sales, zaś wymiar: Cal. Year/month.
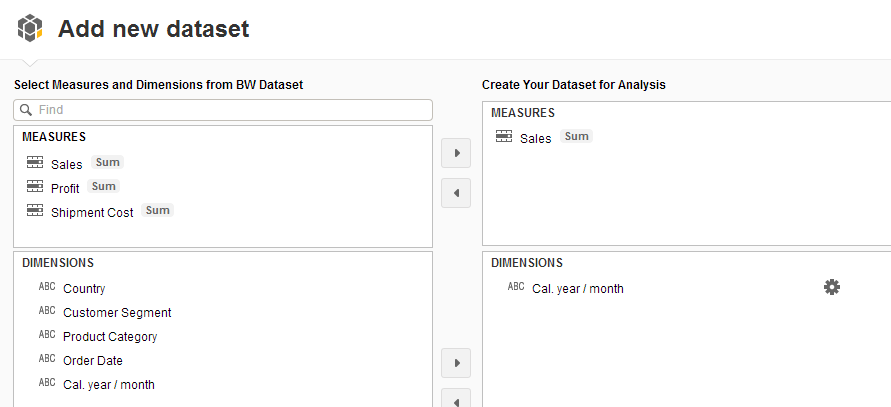
Wskazanie miar i wyników do analizy
- Przygotowanie danych
Sekcja przygotowania danych umożliwia użytkownikowi m.in. filtrowanie danych, przekształcanie, zmianę wartości, tworzenie formuł zarówno dla miar i wymiarów, łączenie wymiarów, grupowanie wartości itp. W analizowanym uproszczonym przypadku nie są konieczne żadne dodatkowe czynności związane z obróbką danych wejściowych do modelu.
- Wybór algorytmów
W kolejnym kroku należy skonfigurować obliczenia, które mają być przeprowadzone na analizowanym zbiorze danych. Mogą one obejmować zarówno funkcje związane z przygotowaniem danych (np. normalizacja, filtrowanie, losowanie próbki, obliczenie statystyk), z zapisem danych (np. do pliku CSV) czy właściwe algorytmy umożliwiające oszacowanie modelu (np. sieci neuronowe, drzewa decyzyjne, klasyfikacje, modele regresji, analiza szeregów czasowych, identyfikacja wartości skrajnych). Za pomocą drag & drop oraz diagramu należy wskazać kolejność wykonywanych obliczeń. W tym miejscu możliwe jest również wykorzystanie własnych skryptów R.
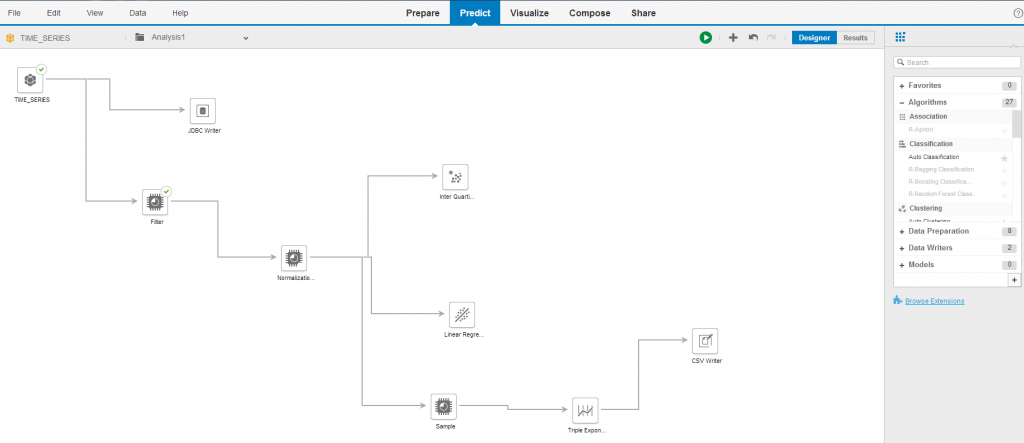
Wybór algorytmu. Wskazanie kolejności obliczeń
- Konfiguracja obliczeń
Przedsiębiorstwo Y w ostateczności zdecydowało się w poprzednim kroku wykorzystać jedynie algorytm Triple exponential smoothing do analizy szeregów czasowych. W jego konfiguracji wystarczyło wskazać typ wyniku (prognoza), liczbę okresów prognozowanych (12), zmienną objaśnianą (Sales), wartość okresu (miesiąc) oraz nazwę kolumny dla wartości otrzymanych na podstawie modelu. Po konfiguracji możliwe jest wykonanie obliczeń.
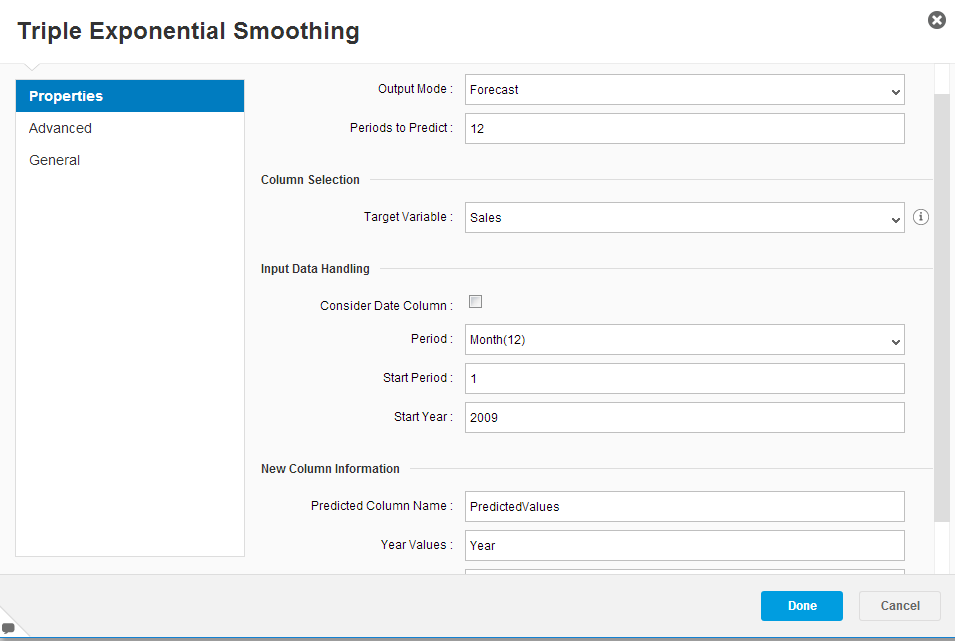
Konfiguracja obliczeń
- Analiza wyników
Analiza wyników umożliwia przegląd wartości rzeczywistych oraz tych otrzymanych na podstawie modelu, wgląd do statystyk opisujących właściwości modelu i jego zdolności predykcyjne oraz wyświetlenie wykresu porównującego obie wartości.
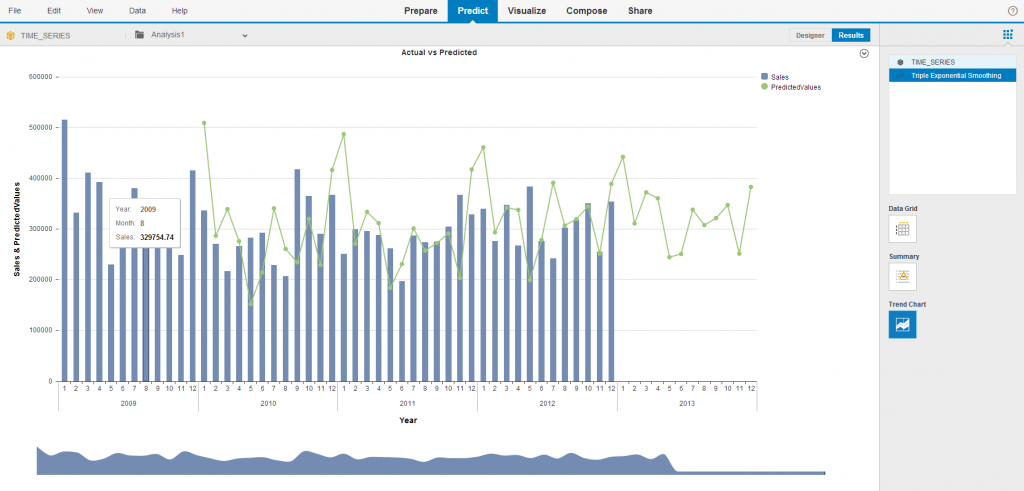
Analiza wyników
- Wizualizacja uzyskanych wyników
W oparciu o dostępne dane narzędzie umożliwia tworzenie zaawansowanych wykresów danych, w tym wykresów kolumnowych, liniowych, kołowych, mieszanych, wodospadowych, map geograficznych i ciepła, a także przedstawianie danych w postaci tabel.
- Konstruowanie raportu
Po skonfigurowaniu tabel i wykresów, które mają prezentować otrzymane wyniki możliwe jest zdefiniowanie infografiki lub dashboardu. Wykorzystać w tym celu można dodatkowo pola tekstowe, rysunki czy pola umożliwiające selekcję danych.
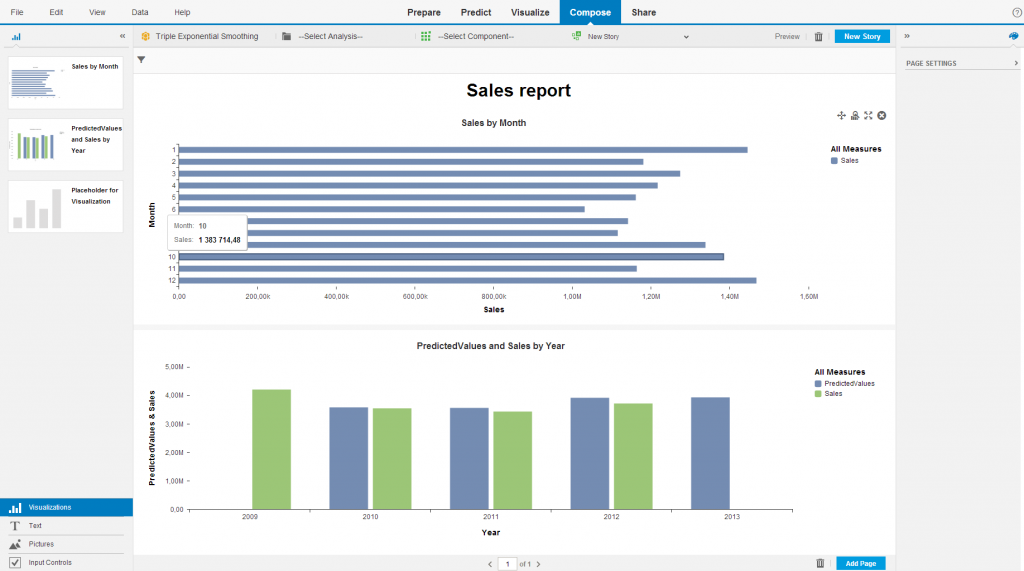
- Publikacja
Wyniki przeprowadzonej analizy można zapisać m.in. do pliku, opublikować na platformie BI lub SAP HANA. Otrzymana prognoza może pomóc podjąć decyzje z zakresu zakupu surowców, planowania wykorzystania zasobów ludzkich czy dalszych działań marketingowych.
Możliwości wykorzystania analiz predykcyjnych w organizacji do podejmowania decyzji na każdym szczeblu zarządzania są praktycznie nieograniczone. Powyżej przedstawiono jedynie przykłady. Ich zastosowanie staje się powoli koniecznością, by pozostać konkurencyjnym w przyszłości i by właściwie spełniać oczekiwania klientów czy kontrahentów. Warto w tym celu wykorzystywać narzędzie, które pozwoli na automatyzację i tym samym ograniczenie czasochłonności całego procesu modelowania. Jednocześnie umożliwi zastosowanie bardziej skomplikowanych algorytmów czy analizę dużych zestawów danych. Dobrze, by było również kompatybilne z istniejącymi już w organizacji systemami i programami SAP. Wszystkie te wymagania spełnia właśnie SAP Predictive Analytics.