
Każdy, kto korzystał z klasycznej hurtowni danych, takiej jak SAP BW, SAP BW/4HANA bądź analogicznych rozwiązań innych dostawców, wie, jak niezastąpione jest to narzędzie w środowisku raportowym opartym na wielu systemach źródłowych bądź wymagającym skomplikowanych przekształceń danych. Od systemów hurtownianych on-premise SAP Datasphere odróżniają niewątpliwie trzy aspekty:
- intuicyjność i łatwość implementacji,
- skalowalność,
- architektura rozwiązania oparta na widokach.
Wszystkie wymienione czynniki nie tylko pozwalają w pełni zintegrować dane pochodzące z różnych systemów źródłowych, ale także sprawiają, że wdrażanie jak i użytkowanie SAP Datasphere jest niezwykle proste. Dużą część czynności związanych z modelowaniem bądź udostępnianiem danych w SAP Datasphere mogą wykonywać kluczowi użytkownicy biznesowi, a nie tylko konsultanci lub pracownicy IT.
Artykuł został podzielony na cztery części. Opisują one systemy źródłowe, sposób przekształcania danych czy współpracę i udostępnianie informacji pomiędzy użytkownikami. Ostatnia część pokazuje, czemu hurtownia danych w nowej odsłonie wykazuje niższe koszty implementacji oraz cechuje się łatwiejszym i szybszym wdrożeniem niż rozwiązania klasyczne.
Systemy źródłowe
SAP Datasphere pozwala połączyć się z systemami źródłowymi z użyciem 31 typów połączeń. Umożliwiają one pobieranie danych zarówno z systemów on-premise, jak i rozwiązań opartych na chmurze. Wśród wspieranych systemów źródłowych należy wymienić:
- systemy SAP: S/4HANA, ECC, z których dane mogą być pobierane bezpośrednio z tabel, ekstraktorów oraz widoków CDS;
- hurtownie danych: SAP BW, SAP BW/4HANA;
- pozostałe systemy SAP: SuccessFactors, Fieldglass, Marketing Cloud;
- rozwiązania oparte na chmurze: Google, Microsoft Azure, Amazon;
- bazy danych: SAP HANA, Microsoft SQL Server, Oracle i inne;
- usługi OData;
- pliki płaskie.
W tym miejscu warto zaznaczyć, że źródłem danych dla SAP Datasphere mogą być nie tylko nowe lub względnie nowoczesne systemy źródłowe. W przypadku SAP ECC z sukcesem udało się nam pozyskać dane również ze środowisk starszych, jak np. SAP ECC 6.0 w wersji SAP ABAP 7.0.
Z założenia SAP Datasphere w dużej części oparty jest na widokach, a dane nie muszą być przechowywane fizycznie w hurtowni danych, aby można było efektywnie wykorzystywać je do raportowania. Konfiguracja źródeł danych w dużej części lub w całości może być oparta na tabelach zdalnych (remote tables). Niewątpliwie atutem takiego rozwiązania są zawsze aktualne dane, które nie muszą być regularnie importowane z systemów źródłowych, a także brak redundancji danych, oszczędność zasobów pamięci oraz ujednolicenie uprawnień.
W dalszym ciągu wspierany jest również cykliczny import danych do hurtowni SAP Datasphere oraz tworzenie łańcuchów przetwarzania danych. Ma to znaczenie w szczególności dla systemów źródłowych starszego typu, opartych na bazie danych o niższej wydajności.
Modelowanie danych
Obszar modelowania danych w SAP Datasphere został podzielony na dwie sekcje:
- Data Builder umożliwia tworzenie tabel, widoków, łączenie danych, a także definiowanie łańcuchów zadań. Widoki mogą być tworzone za pomocą graficznego interfejsu lub klasycznych zapytań SQL. W tym miejscu następuje odwołanie do tabel, widoków lub ekstraktorów znajdujących się po stronie systemów źródłowych;
- Business Builder służy przede wszystkim do tworzenia wymiarów, modeli lub zbiorów danych spójnych z punktu widzenia biznesowego. Obiekty utworzone w tej części korzystają z tego, co zostało już zaimplementowane w sekcji data builder. W tej sekcji konfigurowane są również uprawnienia do danych.
Graficzny interfejs znacznie ułatwia tworzenie poszczególnych modeli danych i ich transformację. W szczególności z jego pomocą możliwe jest zdefiniowanie:
- filtrowania danych – z wykorzystaniem m.in. funkcji numerycznych, tekstowych czy daty z przypisaniem wartości na stałe lub za pomocą parametrów;
- projekcji – czyli ograniczanie liczby wyświetlanych kolumn;
- nowych kalkulacji – obejmujących nowe wymiary, wskaźniki ograniczone oraz formuły, a także konwersję walut;
- agregacji danych;
- łączenia danych – za pomocą operacji union oraz join (wszystkie typy);
- innych, bardziej zaawansowanych funkcji.
Na każdym etapie modelowania możliwy jest podgląd danych, tak by móc na bieżąco monitorować wprowadzone modyfikacje. Ponieważ zdecydowana większość modelowania oparta jest na widokach, podgląd danych dostępny jest od razu, bez konieczności ich przeładowania.
Utworzone widoki czy zbiory analityczne mogą być udostępniane innym użytkownikom oraz na zewnątrz. Tym samym mogą stanowić źródło danych dla innych systemów czy podstawę do tworzenia raportów po stronie SAP Analytics Cloud oraz dedykowanych ku temu środowisk różnych dostawców.
SAP Datasphere
– hurtownia danych w chmurze
-

- SAP Datasphere pozwala połączyć się z systemami źródłowymi z użyciem 31 typów połączeń. Pozwalają one na pobieranie danych zarówno z systemów on-premise, jak i rozwiązań opartych na chmurze
-
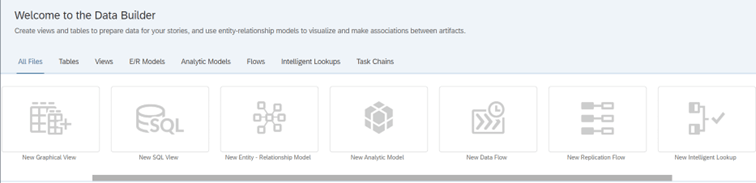
- Data Builder umożliwia tworzenie tabel, widoków, łączenie danych, a także definiowanie łańcuchów zadań
-
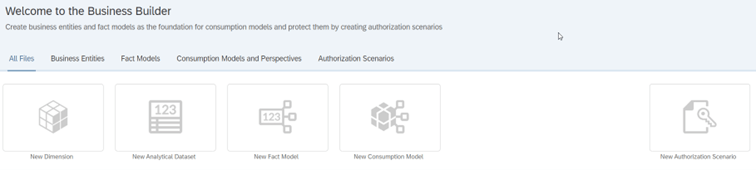
- Business Builder służy przede wszystkim do tworzenia wymiarów, modeli lub zbiorów danych spójnych z punktu widzenia biznesowego
-
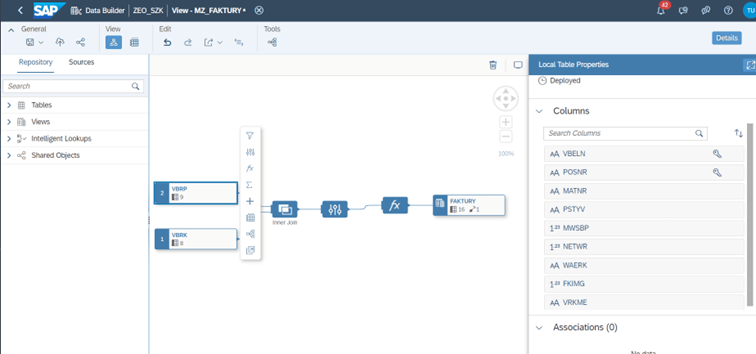
- Tworzenie modeli danych i ich transformacja odbywa się w interfejsie graficznym
-
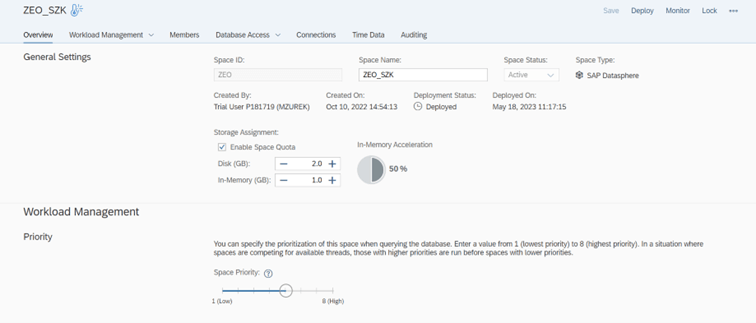
- Architektura SAP Datasphere jest oparta na tzw. przestrzeniach (space)
Współpraca i uprawnienia
Architektura SAP Datasphere jest oparta na tzw. przestrzeniach (space). Do każdej przestrzeni przydzielone są zasoby pamięci oraz użytkownicy mający do niej dostęp. Na jej poziomie definiuje się również połączenia do systemów źródłowych. Warto zaznaczyć, że obiekty pomiędzy przestrzeniami można udostępniać, tak by utworzone i działające modele były dostępne dla pozostałych użytkowników hurtowni danych. W SAP Datasphere przestrzenie stanowią podstawę do wydzielania środowisk roboczych dla różnych zespołów projektowych.
Oprócz przypisania użytkowników do poszczególnych przestrzeni możliwe jest oczywiście konfigurowanie uprawnień. W SAP Datasphere tworzenie scenariuszy uprawnień dostępne jest w sekcji business builder. Na ich podstawie można ograniczać dane dostępne dla użytkowników do konkretnych wartości poszczególnych wymiarów, np. danego zakładu. Możliwe jest również tworzenie ról uprawnień nadających użytkownikom dostęp do odczytu bądź zmiany poszczególnych typów obiektów w SAP Datasphere.
Koszty wdrożenia i skalowalność
Wdrożenie SAP Datasphere jest znacznie bardziej atrakcyjne kosztowo niż miało to miejsce w przypadku klasycznych hurtowni danych on-premise. Składają się na to dwa podstawowe czynniki:
- SAP Datasphere jest rozwiązaniem chmurowym, co oznacza brak ponoszenia wydatków związanych z zakupem i konfiguracją odpowiednich serwerów czy baz danych. W tym zakresie jedynym kosztem jest subskrypcja.
- W SAP Datasphere, w przeciwieństwie do SAP BW, nie ma konieczności tworzenia poszczególnych obiektów przed zaczytaniem danych. Przykładowo w klasycznym SAP BW zaczytanie danych podstawowych dla materiału wiązało się z koniecznością zdefiniowania po stronie hurtowni cechy materiał wraz z określeniem typu danych poszczególnych jej atrybutów. Konieczne było zdefiniowanie też odpowiedniego przepływu danych obejmującego transformację, infopakiety czy procesy DTP. W przypadku standardowych obiektów duża część mogła być aktywowana z tzw. BI Contentu. W dalszym ciągu jednak wdrożenie klasycznej hurtowni SAP BW było znacznie bardziej czasochłonne niż jest to obecnie w przypadku SAP Datsphere.
Oparcie hurtowni danych SAP Datasphere na chmurze przekłada się również na jej łatwą skalowalność. W przypadku jej rozwoju nie jest konieczne ponoszenie dodatkowych nakładów związanych ze zwiększeniem dostępnych zasobów, a jedynie wykupienie dodatkowej subskrypcji pozwalającej na przechowywanie większej ilości danych.
Po przedstawieniu zalet i właściwości SAP Datasphere może nasuwać się pytanie, co z istniejącymi, być może rozbudowanymi systemami SAP BW lub SAP BW/4HANA? Dotychczas poniesione nakłady związane z implementacją rozwiązania nie muszą, a nawet nie powinny być zmarnowane. SAP Datasphere umożliwia migrację istniejących przepływów danych za pomocą narzędzia BW Bridge.
Wszystko to sprawia, że SAP Datasphere wydaje się atrakcyjnym rozwiązaniem zarówno dla dotychczasowych użytkowników systemów hurtownianych, jak i tych, którzy odczuwają potrzebę implementacji środowiska integrującego dane z różnych systemów źródłowych, ale dotychczas ze względu na złożoność wdrożenia i wysoki koszt nie mają jeszcze tego typu rozwiązania.
Przyjazny interfejs, łatwość implementacji i zarządzania, a także szerokie możliwości przekształcania danych stanowią niewątpliwe wyróżniki SAP Datasphere na tle innych hurtowni danych. W dobie informatyzacji analiza danych z wykorzystaniem coraz większej liczby źródeł wydaje się koniecznością w celu szybkiego podejmowania właściwych decyzji i pozostania organizacją konkurencyjną na danym rynku.