
Jak sprawić, by klient kupił więcej niż początkowo zamierzał. Jak najlepiej dobrać asortyment, zorganizować jego układ w sklepie, zaprojektować ulotki reklamowe czy zaplanować akcje promocyjne. Analiza zachowań klientów to bardzo szeroka dziedzina. W dużych sieciach handlowych głowią się nad tym całe działy marketingu i analiz konsumenckich.
Zadanie nie jest proste. Zwykle pociąga za sobą konieczność przeprowadzenia zakrojonych na szeroką skalę badań ankietowych wśród klientów, wnikliwej obserwacji ich zachowań w sklepie czy zatrudnienia wyspecjalizowanych agencji marketingowych i reklamowych. Tymczasem nie musi być ono aż tak skomplikowane, pracochłonne i drogie. Z pomocą przychodzą bowiem informatyczne narzędzia eksploracji danych (Data Mining), a zwłaszcza dostępna w ich ramach analiza koszykowa (ang. market basket analysis).
Co będzie w koszykach klientów?
Wspomniana analiza koszykowa w narzędziach eksploracji danych jest oparta na przechowywanych danych transakcyjnych, dotyczących pojedynczego zakupu. Pozwala ona na wskazanie zestawów produktów zwykle kupowanych łącznie oraz tych, których obecność warunkuje zakup określonych produktów w przyszłości, a także obliczenie prawdopodobieństwa wystąpienia tych zdarzeń. Służy to:
- lepszemu dopasowaniu oferty, tak aby zwiększyć sprzedaż danego produktu dzięki znajomości reguł dotyczących tego, jakie inne produkty kupują klienci, zanim zdecydują się na jego zakup,
- określeniu, jak wycofanie produktu z asortymentu wpłynie na sprzedaż powiązanych produktów, dzięki znajomości reguł dotyczących takich zachowań klientów, w których zakup wybranego produktu determinował zakup pozostałych,
- właściwemu rozmieszczeniu asortymentu – co dotyczy zarówno ustawienia produktów współkupowanych w sąsiedztwie, jak i gdy zależność jest wystarczająco silna – z dala od siebie, by wymusić większy ruch między półkami,
- planowaniu trafnych kampanii promocyjnych – poprzez obniżanie ceny na kolejne współkupowane produkty,
- ustaleniu właściwej wielkości zamówienia produktu – jeśli w ostatnim czasie dobrze sprzedają się inne produkty, po których w określonych odstępach czasowych jest on nabywany.
Działanie BO Predictive Workbench jest oparte na budowaniu strumieni danych stanowiących sekwencję operacji na rekordach danych, poczynając od ich pozyskania, poprzez przetworzenie i analizę, a kończąc na eksporcie wyników
Sama hurtownia danych nie jest w stanie sprostać temu zadaniu, choć oczywiście mogą w niej być przechowywane szczegółowe dane transakcyjne dotyczące zakupów. Niestety tak ogromne ilości informacji, sięgające w przypadku dużych sieci handlowych milionów transakcji dziennie, są trudne do analizowania.
Systemy wspierające podejmowanie decyzji (OLAP, OnLine Analytical Processing) pozwalają pozyskać jak najwięcej szczegółowych informacji, ale nadal to użytkownik sam jest odpowiedzialny za identyfikację określonych powiązań, od których uzależnia przeprowadzaną analizę.
A jednak przechowywane w hurtowni danych informacje o dotychczasowej działalności przedsiębiorstwa, wielkości oraz strukturze sprzedaży oraz cechach klientów mogą zostać użyte do podejmowania tego typu decyzji dzięki wykorzystaniu dodatkowego narzędzia do eksploracji danych, jakim jest BussinessObject Predictive Workbench.
Ku integracji z SAP BW
BussinessObject Predictive Workbench nie jest narzędziem nowym na rynku produktów Data Mining. Pierwsze wersje oprogramowania dostarczane przez brytyjską firmę Integral Solutions Limited (ISL) były oparte na systemie UNIX i przeznaczone tylko dla firm konsultingowych. Równocześnie było to pierwsze narzędzie eksploracji danych posiadające graficzny interfejs użytkownika i niewymagające znajomości języków programowania.
W 1999 r. przedsiębiorstwo zostało wykupione przez działającą na rynku analiz statystycznych firmę SPSS, która dostrzegła ogromny potencjał tego narzędzia. Kolejne wersje oparto na architekturze klient-serwer, przeznaczono do użytku komercyjnego, a także dostosowano do wymogów systemu Windows. Do wersji 12. włącznie, wydanej w roku 2008, aplikacja nazywała się Clementine, zaś od wersji 13. było to SPSS Predictive Analytics Software (PASW). Od momentu przejęcia SPSS przez IBM w 2009 r. oprogramowanie nazywa się IBM SPSS Modeler.
Samo narzędzie BussinessObject Predictive Workbench jest efektem porozumienia zawartego w 2007 r. pomiędzy IBM a firmą BusinessObjects, które umożliwiło integrację wówczas jeszcze programu Clementine z platformą BusinessObjects. Po przejęciu firmy przez SAP rozwiązanie zostało dołączone do oferty tego producenta.
BussinessObject Predictive Workbench dostarcza wszystkich funkcjonalności narzędzia dostępnych w pierwotnej wersji sygnowanej przez SPSS. Dodatkowo wersja 12. BO Predictive Workbench umożliwia integrację ze światem obiektów BO, zaś wersja 13. – również z hurtownią danych SAP BW 7.x. Oprogramowanie może zarówno działać w oparciu o architekturę klient-serwer, jak i zostać zainstalowane tylko na jednym komputerze.
Dane w strumieniu
Działanie narzędzia jest oparte na budowaniu strumieni danych, które stanowią sekwencję operacji wykonywanych na rekordach danych, poczynając od ich pozyskania, poprzez przetworzenie i analizę, a kończąc na eksporcie otrzymanych wyników.
By móc eksplorować dane, najpierw należy je pozyskać oraz przetworzyć. Niewątpliwą zaletą BussinessObject Predictive Workbench jest możliwość pozyskiwania danych z wielu różnych źródeł, obejmujących nie tylko pliki płaskie, ale także relacyjne bazy danych, świat obiektów czy zapytania BW.
Dla plików możliwe jest zaczytywanie danych z plików tekstowych rozdzielanych przecinkiem, średnikiem lub innym wskazanym znakiem interpunkcyjnym, plików tekstowych o stałej, niezmiennej szerokości kolumn czy też plików utworzonych w programach MS Excel, SAS i SPSS Statistics. Źródło baz danych może pozyskać dane za pomocą połączeń ODBC zarówno z Microsoft SQL Server, DB2, Oracle jak i wielu innych. Warunkiem jest jedynie prawidłowo zainstalowane i skonfigurowane połączenie ODBC.
Możliwe jest nie tylko pozyskiwanie danych z konkretnych tabel, ale także różnego rodzaju wglądów – poprzez formułowanie odpowiednich zapytań w języku SQL bezpośrednio z poziomu narzędzia. Jeśli dodatkowo prawidłowo skonfigurowane są wglądy przedsiębiorstwa, aplikacji oraz dostawcy informacji, można również pozyskiwać do analizy dane z różnego rodzaju repozytoriów. Jednym z nich – oferującym najszersze spektrum danych i możliwości ich przetwarzania – jest hurtownia danych SAP BW. Dane z SAP BW można pozyskiwać na dwa sposoby.
Pierwszym jest wykorzystanie komponentu Świat obiektów, który umożliwia wybranie właściwego zestawu obiektów BusinessObject, a następnie zbudowanie w oparciu o niego zapytania zwracającego interesujące dane. Samo zapytanie tworzy się w uruchomionym z poziomu Predictive Workbench interfejsie, działającym na zasadzie analogicznej do BO Webi i umożliwiającym wybór odpowiednich wskaźników, wymiarów, obiektów oraz ograniczanie zwracanych wartości.
Drugą metodą pozyskania danych jest użycie komponentu umożliwiającego bezpośredni dostęp do danych znajdujących się w hurtowni danych SAP BW. Możliwy jest wybór właściwego zapytania, a także określenie cech i wskaźników, które mają być poddane analizie.
Pewnym ograniczeniem jest fakt, iż sposób ten może być wykorzystywany tylko w przypadku zapytań SAP BW v. 7.x. W przypadku wersji SAP BW 3.5 dane z raportów mogą być pozyskane do BO Predictive Workbench, ale tylko przy zastosowaniu rozwiązania pierwszego – czyli świata obiektów.
Obróbka danych
Zanim przystąpi się do analizy koszykowej czy też innej z zakresu Data Mining, pozyskane dane można i należy poddać obróbce i przygotowaniu. BO Predictive Workbench umożliwia zarówno działania na poziomie rekordów, jak i konkretnych pól. W przypadku obróbki danych na poziomie rekordów możliwa jest przede wszystkim ich selekcja (filtrowanie), agregacja, sortowanie czy łączenie.
Ponadto na tym etapie możliwa jest agregacja RFM (Recency, Frequency, Monetary), która pozwala na analizę klientów pod względem daty ostatniego zakupu, całkowitej liczby i wartości dokonanych transakcji, a następnie uszeregowanie klientów według tych trzech kryteriów i przypisanych im wag.
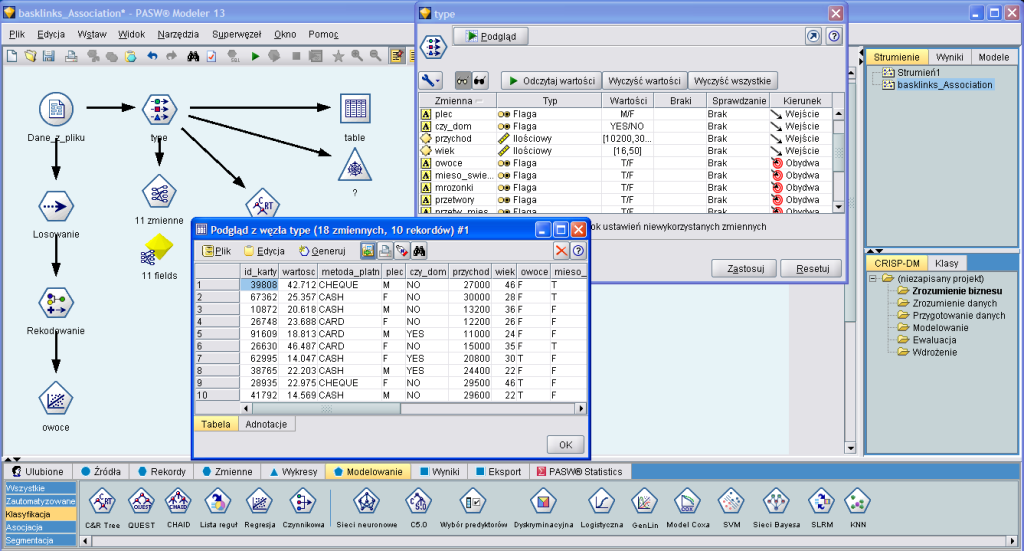
Budowa zapytania na tle graficznej reprezentacji strumienia danych
Działanie na konkretnych polach pozwala na przygotowanie danych i przypisywanie im odpowiednich typów. Komponenty należące do tej grupy umożliwiają przede wszystkim definiowanie typów danych (np. porządkowe, ilościowe, flagowe), wybór pól oraz zmianę ich nazw, przeliczanie wartości (formuły) czy zastępowanie brakujących danych konkretnymi wartościami. Tak przedstawione dane można oczywiście zaprezentować na jednym z dostępnych typów wykresów, między innymi liniowym, kolumnowym czy sieciowym.
Po przygotowaniu danych można przystąpić do właściwej analizy Data Mining. Jedną z dostępnych metod jest analiza koszykowa, w przeciwieństwie do tradycyjnych drzew decyzyjnych pozwalająca na wykrycie wielu zależności i wyciągnięcie różnych wniosków. W związku z tym że jest to metoda deskryptywna, nie może zostać bezpośrednio wykorzystana do prognozowania wielkości sprzedaży w przyszłości. Niemniej pozwala ona w prosty sposób wykryć zależności pomiędzy kupowanymi produktami, które prezentowane są zarówno w postaci tabeli, jak i wykresu sieciowego.
To, jak ważne dla sieci handlowej jest ustalenie powiązań pomiędzy kupowanymi produktami, omówiono na początku artykułu. Z poziomu BO Predictive Workbench dostępne są trzy algorytmy służące analizie koszykowej: GRI, sekwencyjny oraz najbardziej rozpowszechniony algorytm Apriori.
Ten ostatni algorytm działa najszybciej, co ma szczególne znaczenie zwłaszcza przy dużej liczbie danych. Dodatkowo nie ma ograniczeń co do liczby zwracanych zależności, a dzięki pięciu dostępnym metodom uczenia się możliwe jest bardziej efektywne dostosowanie algorytmu do posiadanych danych.
Wynik działania algorytmu prezentowany jest w tabeli, w której w ujęciu procentowym wskazane jest, jak często produkty A i B kupowane są łacznie oraz w ilu procentach dokonywanych zakupów produktu A nabywany jest również produkt B. Przy czym A (tzw. poprzednik) nie musi stanowić pojedynczego produktu, ale reprezentować grupę kilku. I tak na przykład z przeprowadzonej analizy można uzyskać informację, iż w danym okresie 17% transakcji dotyczyło kupna zarówno piwa, przetworów jak i mięsa mrożonego. Z kolei 87% klientów, którzy zdecydowali się na zakup piwa i przetworów, kupiło również mrożonki.
To, jak duża będzie dopuszczalna liczba poprzedników i czy analizowane będą tylko powiązania po-między produktami rzeczywiście kupowanymi łącznie, czy też pomiędzy wybranymi produktami bez względu na istotność relacji pomiędzy nimi, zależy od użytkownika i jest w pełni konfigurowalne. Dodatkowo relacje pomiędzy kupnem poszczególnych produktów można przedstawić na wykresie sieciowym, na którym grubość linii odzwierciedla siłę istniejących powiązań.
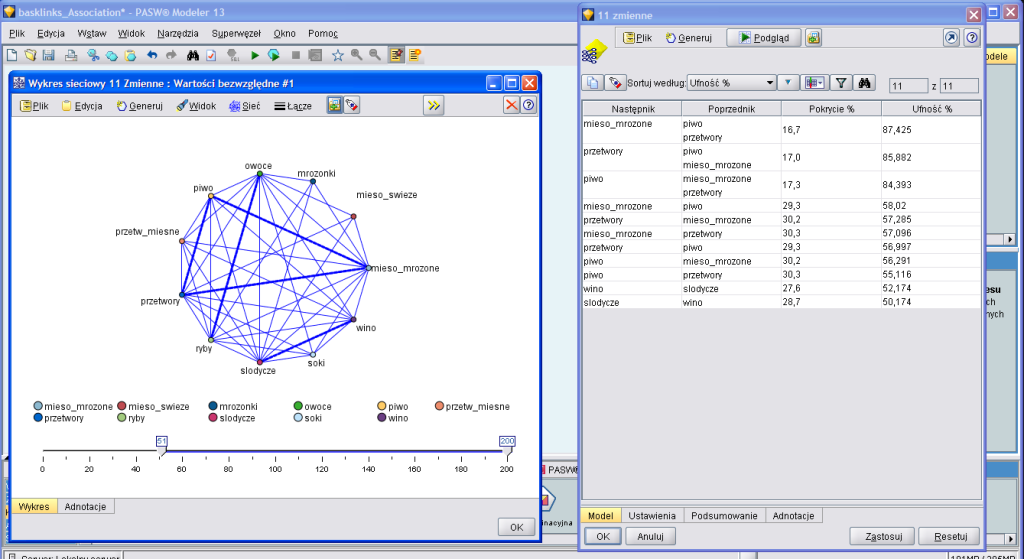
Tabela i wykres sieciowy zależności pomiędzy kupowanymi produktami – przykład
Nie tylko koszyk
Data Mining to jednak nie tylko analiza koszykowa. Narzędzie BO Predictive Workbench pozwala na klasyfikację i segmentację klientów oraz prognozowanie sprzedaży. Oprócz powszechnie stosowanych w tego typu aplikacjach drzew decyzyjnych, w narzędziu dostępne są algorytmy oparte na sieciach bayesowskich czy neuronowych.
Możliwa jest także analiza głównych składowych, która może przyczynić się do wskazania podstawowych czynników determinujących zakup danego produktu, oraz modele regresji liniowej, średniej ruchomej, w oparciu o które można dokonywać prognozy wielkości sprzedaży w przyszłości. Wybór właściwego modelu ułatwia wykres ewolucyjny, który porównuje generowane przez modele predyktywne wyniki.
Wszystkie te metody klasyfikacji pozwalają z odpowiednim prawdopodobieństwem ustalić, czy dany klient w przyszłości zdecyduje się na zakup produktu A, czy też nie, lub też znaleźć grupę klientów, do której najlepiej skierować kampanię promocyjną. Przykładowo, możemy uzyskać informację, iż klient – kobieta, o wysokich dochodach, w wieku 25-35 lat z wysokim prawdopodobieństwem zdecyduje się na zakup płatków śniadaniowych fitness. Działając z kolei na zagregowanych szeregach czasowych dotyczących sprzedaży poszczególnych produktów, możemy dla nich prognozować całkowitą wielkość sprzedaży w przyszłości, stosując zarówno klasyczne modele regresji, uzależniające sprzedaż produktu A od wielkości sprzedaży produktu B, pory roku itp., jak i modele wygładzenia wykładniczego czy średniej ruchomej.
Z kolei metody z modułu segmentacja zalecane są przy identyfikowaniu grup klientów, co ma znaczenie przy projektowaniu różnego rodzaju kampani promocyjnych. Segmentacja przy tym odbywa się na podstawie dokonywanych transakcji, bez jakiejkolwiek początkowej wiedzy na temat grup i ich charakterystyk.
Wartość powstałych modeli jest określana przez ich zdolność do wychwytywania ciekawych grup i dostarczenia ich przydatnych opisów. Modele te są często używane do tworzenia klastrów lub segmentów, które są następnie wykorzystywane jako elementy wyjściowe w kolejnych analizach (np. poprzez segmentację potencjalnych klientów na jednorodne podgrupy).
Przetworzone dane można zapisać w bazie danych, pliku tekstowym, MS Excel, SAS, SPSS statistics. Same zaś uzyskane w wyniku analizy wyniki w postaci tabel, podsumowań czy wykresów najłatwiej zapisać w formacie HTML i w tej postaci przekazywać innym zainteresowanym osobom.
Obecnie narzędzia eksploracji danych są powszechnie stosowane i istnieje wiele konkurencyjnych dostawców tego typu oprogramowania na rynku. Za wyborem Predictive Workbench przemawiają dwa fakty: SPSS od lat jest liderem w oprogramowaniu statystycznym i Data Mining. A co ważniejsze, jest to jedyne dostępne narzędzie umożliwiające integrację z SAP BW.