
And what if you are an IT director who is responsible for efficient IT infrastructure? You know that the company will not be able to bear monthly costs of maintaining two independent data centers. It is also costly to maintain a team of system maintenance specialists, access control security measures, proper conditions for cooling of devices, fire protection measures, power back up, power generators, secure and redundant internet access, etc., and all that on a 24/7 basis, 365 days per year. What then?
Collocation and hosting
One of the solutions is the collocation or hosting of IT environments in data centers (DCs) employing highly specialized IT staff. The collocation of your own hardware or using hosting services in one DC is not all. Especially for critical systems where availability is a key condition, one data center is not sufficient. The availability of the second DC, also called a disaster recovery center (DRC) is necessary.
In the event of a primary DC failure, data stored in DRC may be run in several possible ways, depending on the selected backup/replication/high availability strategy.
Collocation (own hardware)
1. The customer has only a copy of the resources in DRC. To be able to run their systems, the customer must provide hardware (servers, arrays). Most often, the customer reserves the resources that are sufficient for the temporary operation of selected systems. The time needed to restore data depends on the detailed arrangements and ranges from one to several days. A low cost solution, with a long time needed to restore the availability of critical systems.
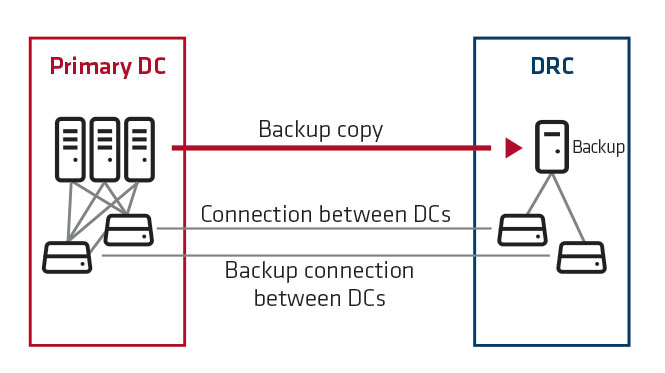
2. The customer has a a backup copy and full hardware resources (similarly as in the case of the primary DC) for running all critical systems. It takes from several to more than a dozen hours to restore data. After recovery from a backup copy, systems are available and ready to accept full load. The customer doubles their infrastructure resources and thus costs, but it still takes several hours to restore the operation of the systems.
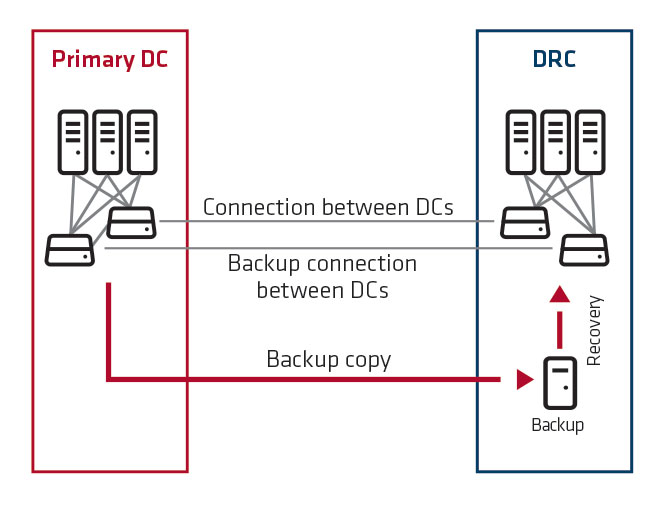
3. In addition to the backup copy, the customer replicates their data to DRC in a continuous mode with a scheduled delay, e.g.: 15 minutes or has synchronous data replication at the array level or at the database level (maintaining high availability clusters in the active-active mode). Dedicated optical fibers must be routed between the centers to ensure the maintenance of synchronous replication. It takes some minutes in the best case to run critical systems in DRC. For high availability solutions where all replicated systems are synchronous, it is possible to build a solution where switching between DCs is done in the manner unnoticeable to the user.
Hosting
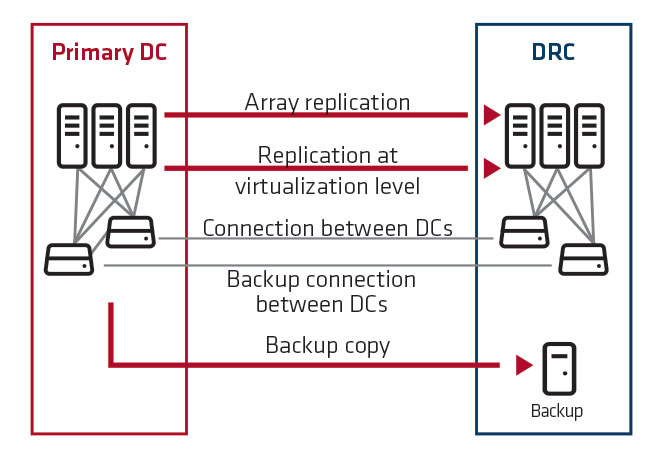
1. The customer maintains IT systems in the primary DC and their backup copies are stored in DRC. If the primary DC is unavailable, the time of recovery from a backup copy depends on detailed arrangements and ranges from 4 hours to 1 day (recovery time is specified only for systems that are subject to cyclical recovery tests in addition to the backup copy). The customer has a guarantee of availability of a sufficient number of hosting platforms for restoring the operation of critical systems in DRC.
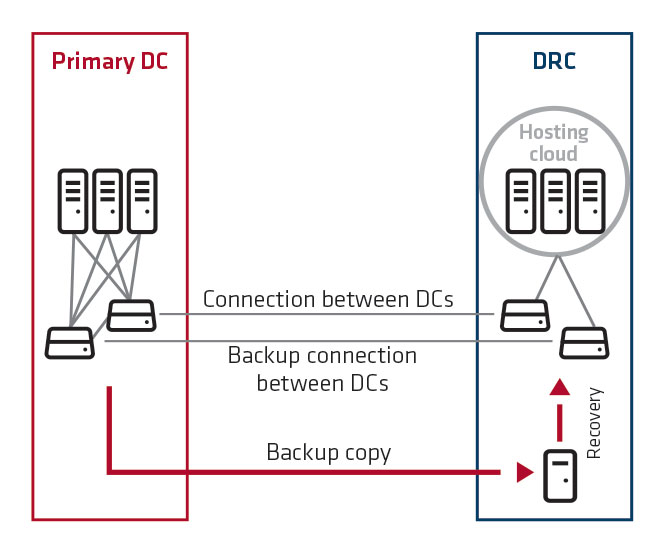
2. The customer maintains IT systems in the primary DC. In DRC, a backup copy is maintained and asynchronic data replication is performed in parallel. The method of replication is selected individually with the customer. If the primary DC is unavailable, startup time in DRC ranges from 15 minutes to several hours.
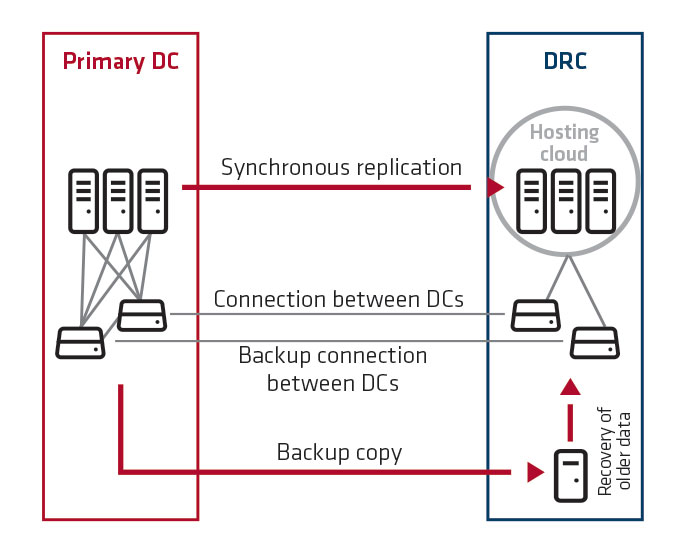
3. The customer maintains IT systems in the primary DC. In DRC, IT systems are replicated synchronously on a continuous basis using high-availability technologies. The customer has fully available systems, without delays in case of unavailability of the primary DC.
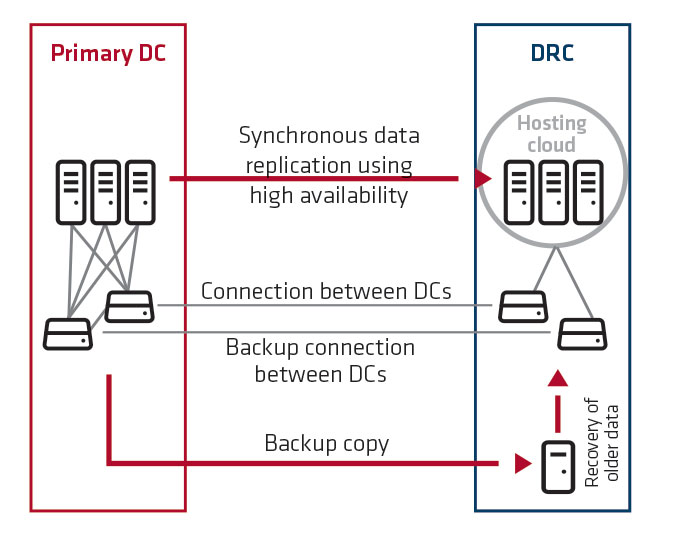
To sum up this comparison, depending on the required level of availability, the customer chooses the solution that is suitable for them and cost-effective. One must keep in mind that any solution, even the simplest one, requires repeatable cyclic startup tests in DRC. A backup copy remains only an illusion of security if no tests are performed to confirm the correctness of restoring full availability of the environment.
Twin data centers
All for One Data Centers are two twin data centers supported by a team of over 50 specialists. BCC (now All for One Poland) provides multiple customers with collocation in two centers simultaneously, allowing for full or partial replication/synchronization. For selected customers who require high availability, BCC provides hosting with various pre-set availability levels and DRC services in various variants.
All for One Data Centers are not just walls, burglary protection, air conditioning, power supply or gas fire suppression systems. It is also a well-thought-out solution that allows the capabilities of both twin DCs to be fully leveraged. Examples include two independent fiber optic routes connecting data centers, different power connections in separate paths, or limiting access to DCs only to some employees with valid certificates confirming their knowledge of the solutions used in the data centers.